A Look at Finance Part 6: Real-World Portfolio Optimization
In this post we extend the analysis of the previous post into the case where our portfolio is comprised of more than 1 asset/instrument. This is an important extension since it offers a genuine optimization problem that requires a sophisticated numerical technique rather than the one-dimensional, parametric search used in the last example.
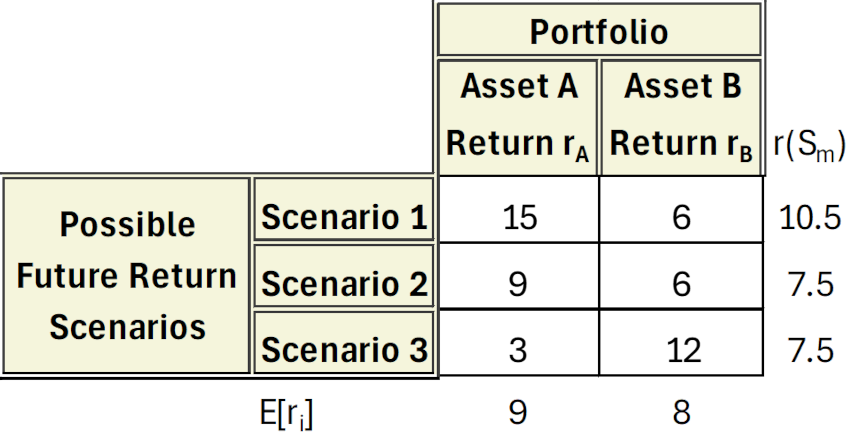
For this case, we again turn to van der Wijst’s examples in his Chapter 3. The specific case is found in Section 3.2.2 under the whimsical story or helping our ‘Uncle Bob’. The narrative starts with Uncle Bob’s existing portfolio whose fractional division and returns for the past year and estimated returns for the next year can be summarized as follows
| Stock | Ticker Symbol | Fraction | Past Year’s Return | Estimated Return |
|---|---|---|---|---|
| GOOG | 0.1 | 0.000 | 0.080 | |
| Cisco Systems | CSCO | 0.1 | -0.205 | 0.075 |
| Logitech International | LOGI | 0.6 | -0.525 | 0.060 |
| Amazon | AMZN | 0.1 | 0.560 | 0.125 |
| Apple | AAPL | 0.1 | 0.314 | 0.100 |
Obviously, the past year’s returns seem to be radically different from Uncle Bob’s estimations of what will happy in the next year, reflecting that during the past year there was a downturn in computer peripherals (Cisco & Logitech) but healthy sales in core system and related products (Amazon & Apple). This coming year, Uncle Bob feels very strongly that the economic head winds have shifted and van der Wijst urges us not to second guess Uncle Bob but simply to try to rebalance the fractional weights in his portfolio to try to give him a healthy return while minimizing his risk.
van der Wijst provides an aside that if we were tighter with Uncle Bob we would check that he downloaded the past year’s financial data from each of the stocks found within his portfolio and properly calculated the returns as well as the corresponding covariance matrix but that we should trust his results.
Assuming that our less-than-favorite uncle got it right, van der Wijst gives us the individual standard deviations and the corresponding correlation matrix he derived. I won’t bother to repeat those values here but will instead simply give the reconstructed covariance matrix
| GOOG | CSCO | LOGI | AMZN | AAPL | |
|---|---|---|---|---|---|
| GOOG | 0.082 | 0.045 | 0.045 | 0.054 | 0.044 |
| CSCO | 0.045 | 0.132 | 0.047 | 0.042 | 0.039 |
| LOGI | 0.045 | 0.047 | 0.213 | 0.055 | 0.045 |
| AMZN | 0.054 | 0.042 | 0.055 | 0.116 | 0.049 |
| AAPL | 0.044 | 0.039 | 0.045 | 0.049 | 0.062 |
While we are taking some things on faith, we are, at least, happy to see that the covariance matrix is symmetric (as it should be).
Now, the highest possible return Uncle Bob could expect to achieve is 12.5% if he were to put all of his eggs into the Amazon basket but his risk, as represented by $\sigma_{\textrm{AMZN}}$, is 34%. The lowest risk, single stock option is a solo investment into Apple with $\sigma_{\textrm{AAPL}} = 25%$ with a return of 10%. Uncle Bob would like to know if he can get a comparable return with a lower risk.
Mathematically, his goal translates into the following computational optimization problem:
\[ \textrm{Minimize: } \sigma[P] = \sqrt{ \sum_{i,j} f_i f_j \sigma_{ij} } \; \]
\[ \textrm{Subject to: } \left\{ \begin{array}{l} E[P] \ge 0.1 \\ \sum_i f_i = 1 \end{array} \right. \; .\]
Since the objective function $\sigma[P]$ involves the square root of a weighted sum of the squares, the optimization technique that we need to use has to be a non-linear optimizer. A gradient-based method is a good choice and both Microsoft Excel (which van der Wijst seems to reluctantly use while poking some fun at it) and the Scipy package in the Python ecosystem provide this functionality. I choose to implement this within Python.
Since it is easy to confuse what element of an array translates to what ticker symbol, it was easier to use dictionaries for everything except the fractional weights. These dictionaries look like:
tickers = ['GOOG','CSCO','LOGI','AMZN','APPL']
est_rets = {'GOOG':0.080,'CSCO':0.075,'LOGI':0.060,'AMZN':0.125,'APPL':0.100}
ann_std = {'GOOG':0.287,'CSCO':0.363,'LOGI':0.462,'AMZN':0.340,'APPL':0.250}
corr = {('GOOG','GOOG'):1, ('CSCO','CSCO'):1, ('LOGI','LOGI'):1, ('AMZN','AMZN'):1, ('APPL','APPL'):1,
('GOOG','CSCO'):0.43,('GOOG','LOGI'):0.34,('GOOG','AMZN'):0.55,('GOOG','APPL'):0.62,
('CSCO','LOGI'):0.28,('CSCO','AMZN'):0.34,('CSCO','APPL'):0.43,
('LOGI','AMZN'):0.35,('LOGI','APPL'):0.39,
('AMZN','APPL'):0.58}
Note that ann_std and corr are the data structures I used to translate the statistics provided by van der Wijst into a covariance matrix. van der Wijst provided only the lower-diagonal portion of the correlation matrix in a table; the following function constructs a full 5\times5 covariance matrix:
#Symmetrize the data structure to be a full 5x5 correlation matrix
def sym_corr(tickers,corr):
for t1 in tickers:
for t2 in tickers:
key = (t1,t2)
if key in corr:
pass
else:
key1 = (t2,t1)
corr[key] = corr[key1]
return corr
#Combine the correlation matrix with the standard deviations to produce a covariance matrix
def create_cov(tickers,corr):
if len(corr) < len(tickers)**2:
corr = sym_corr(tickers,corr)
cov = {}
for t1 in tickers:
for t2 in tickers:
cov[(t1,t2)] = ann_std[t1]*ann_std[t2]*corr[(t1,t2)]
return cov
The first constraint, that E[P] \ge 10% was implemented by
def calc_port_return(fs,tickers,est_rets):
port_ret = 0
ticker_idx = {v: i for i, v in enumerate(tickers)}
for t1 in tickers:
port_ret += fs[ticker_idx[t1]]*est_rets[t1]
return port_ret
The objective function was implemented by
def calc_port_std(fs,tickers,corr):
ticker_idx = {v: i for i, v in enumerate(tickers)}
cov = create_cov(tickers,corr)
port_var = 0
for t1 in tickers:
for t2 in tickers:
port_var += fs[ticker_idx[t1]]*cov[(t1,t2)]*fs[ticker_idx[t2]]
return np.sqrt(port_var)
Finally, the optimization was performed using:
# targeted return value of 10%
target = 0.10
# list of constraint dictionaries - the first one ensures that the fractional
# weights sum to 1; the second one ensures that at least 10% return is achieved
constraints = [
{'type': 'eq', 'fun': lambda f: np.sum(f) - 1},
{'type': 'ineq', 'fun': lambda f: calc_port_return(f, tickers, est_rets) - target}
]
#provide a list of bounds consistent with each fractional weight having to
#be between 0 and 1
bounds = [(0, 1)] * 5
#provide a first guess for the fractional weights
x0 = np.array([0.2, 0.2, 0.2, 0.2, 0.2])
#run the scipy 'minimize' function
result = minimize(
calc_port_std,
x0,
args=(tickers, corr), # <-- extra args passed here
method='SLSQP',
bounds=bounds,
constraints=constraints,
options={'ftol': 1e-9, 'maxiter': 1000, 'disp': True}
)
The optimizer ran nearly instantaneously and produced the following output
Optimization terminated successfully (Exit mode 0)
Current function value: 0.2357533346589545
Iterations: 9
Function evaluations: 54
Gradient evaluations: 9
The resulting fractional weights are
| Ticker Symbol | Fractional Weight |
|---|---|
| GOOG | 0.12 |
| CSCO | 0.10 |
| LOGI | 0.00 |
| AMZN | 0.19 |
| AAPL | 0.59 |
with a return of 10% with a risk of 23%. We managed to lower the risk from the Apple-only solution by 2% while maintaining the same return. This shows the power of diversification.